Today I was playing around with an LLM called Mistral 7B by running it locally with Ollama. Once installed, Ollama provides a chat interface and an API that you can use and run wherever.
curl http://localhost:11434/api/generate -d '{
"model": "mistral",
"prompt":"tell me a joke?"
}'
When running this API call, I noticed that responses were streamed back to the client in a way that appears to be token by token. Take a look at running the command.
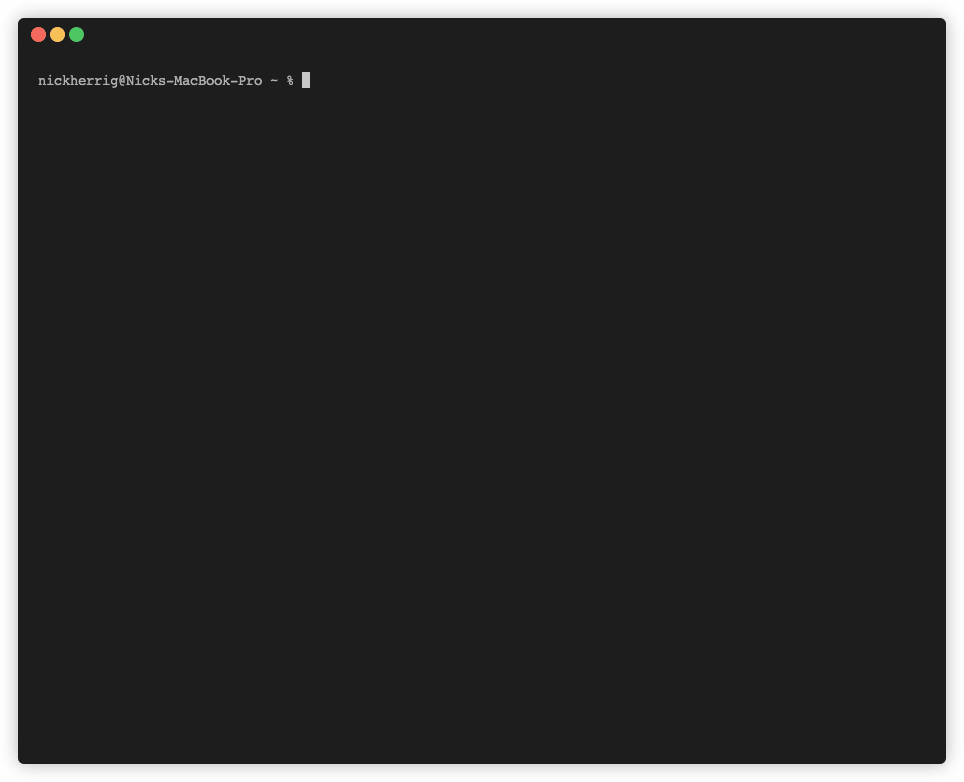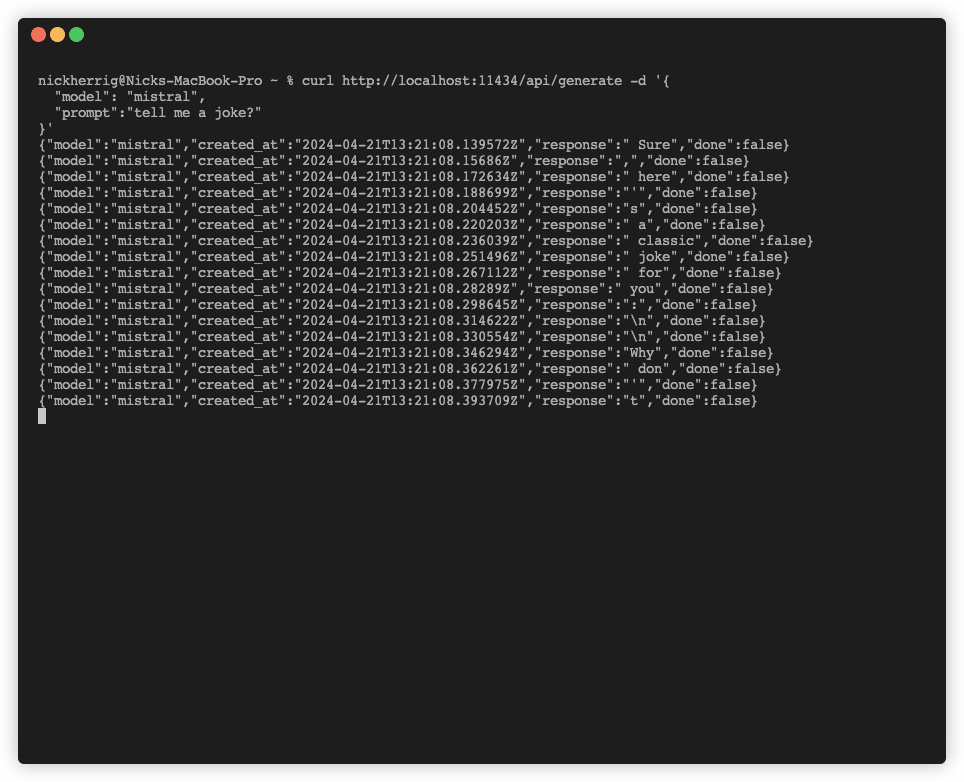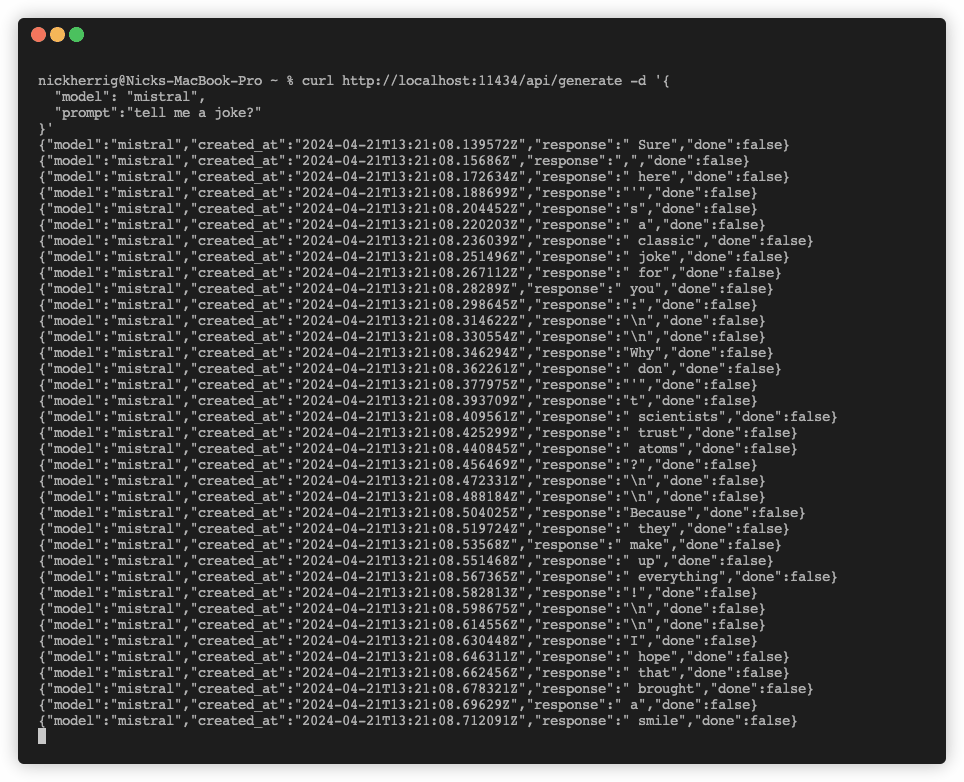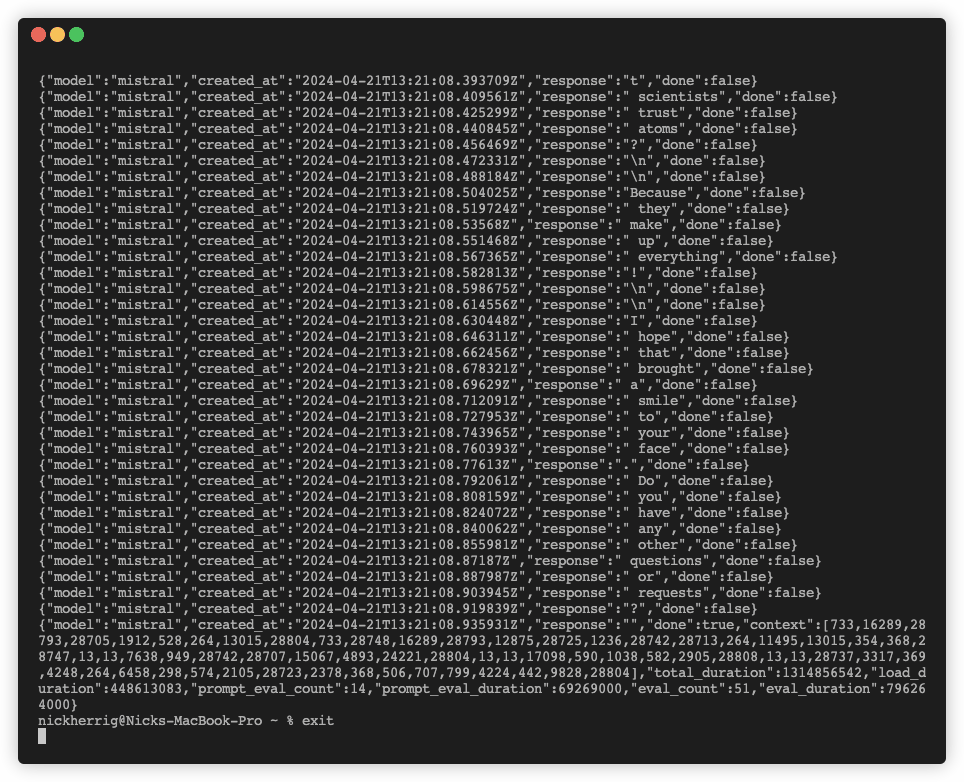
This got me thinking a little bit about how this would work with the Python Requests library. I wrote the code I usually would to interact with a POST request as seen below, wondering if this would workout:
import requests
url = 'http://localhost:11434/api/generate'
data = {
"model": "llama3",
"prompt": "Why is the sky blue?"
}
response = requests.post(url, json=data)
print(response.json())
Boom 💥, broken. It looks like there are some JSONDecodeErrors. Check out the error below:
python3 main.py
Traceback (most recent call last):
File "/Users/nickherrig/git/llms/venv/lib/python3.10/site-packages/requests/models.py", line 960, in json
return complexjson.loads(self.content.decode(encoding), **kwargs)
File "/Users/nickherrig/.pyenv/versions/3.10.13/lib/python3.10/json/__init__.py", line 346, in loads
return _default_decoder.decode(s)
File "/Users/nickherrig/.pyenv/versions/3.10.13/lib/python3.10/json/decoder.py", line 340, in decode
raise JSONDecodeError("Extra data", s, end)
json.decoder.JSONDecodeError: Extra data: line 2 column 1 (char 92)
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/Users/nickherrig/git/llms/main.py", line 11, in <module>
print(response.json())
File "/Users/nickherrig/git/llms/venv/lib/python3.10/site-packages/requests/models.py", line 968, in json
raise RequestsJSONDecodeError(e.msg, e.doc, e.pos)
requests.exceptions.JSONDecodeError: Extra data: line 2 column 1 (char 92)
I did a bit of digging in the Requests library documentation, and you can set stream=True in the request.post() portion of the code.
From there, response has a method iter_lines() which you can loop over as a context window and returns a line of <class 'bytes'>.
Let’s take a look at the updated code:
import requests
import json
url = 'http://localhost:11434/api/generate'
data = {
"model": "llama3",
"prompt": "Tell me a Joke?"
}
response = requests.post(url, json=data, stream=True)
for line in response.iter_lines():
print(type(line))
if line:
decoded_line = line.decode('utf-8')
print(json.loads(decoded_line))
In this script, I’m simply printing the JSON response as it’s streamed in. Ideally, I’d like to see each word/token streamed to stdout as they are received.
This took a little experimenting but ended up finding two parameters that are part of the print() statement: end and flush.
By default, end is set to a newline character which makes sense. Since we’re going after streaming responses word by word, we’ll set this to an empty string "".
By default flush is set to False meaning that output is written to the console only under certain conditions such as when the buffer is full, a newline character is encountered, or the program finishes execution.
Let’s take a look at the updated code:
import requests
import json
url = 'http://localhost:11434/api/generate'
data = {
"model": "llama3",
"prompt": "write me a story about python."
}
response = requests.post(url, json=data, stream=True)
for line in response.iter_lines():
if line:
decoded_line = line.decode('utf-8')
print(json.loads(decoded_line)["response"], end="", flush=True)
And let’s see it in action!
Happy streaming! 🔥