It’s been 2 days since the launch of Llama 3 and I’ve been itching to try it out. Here is a short blog post experimenting with Ollama to locally run this sota (state of the art) LLM (large language model). But first, what is Llama 3?
What is Llama 3
Meta’s Llama 3 is the most capable openly available LLM as of writing this blog. On April 18th, 2024, Meta released two models of this generation with 8B and 70B parameters. Below are a few model performance charts on various LLM benchmarks.
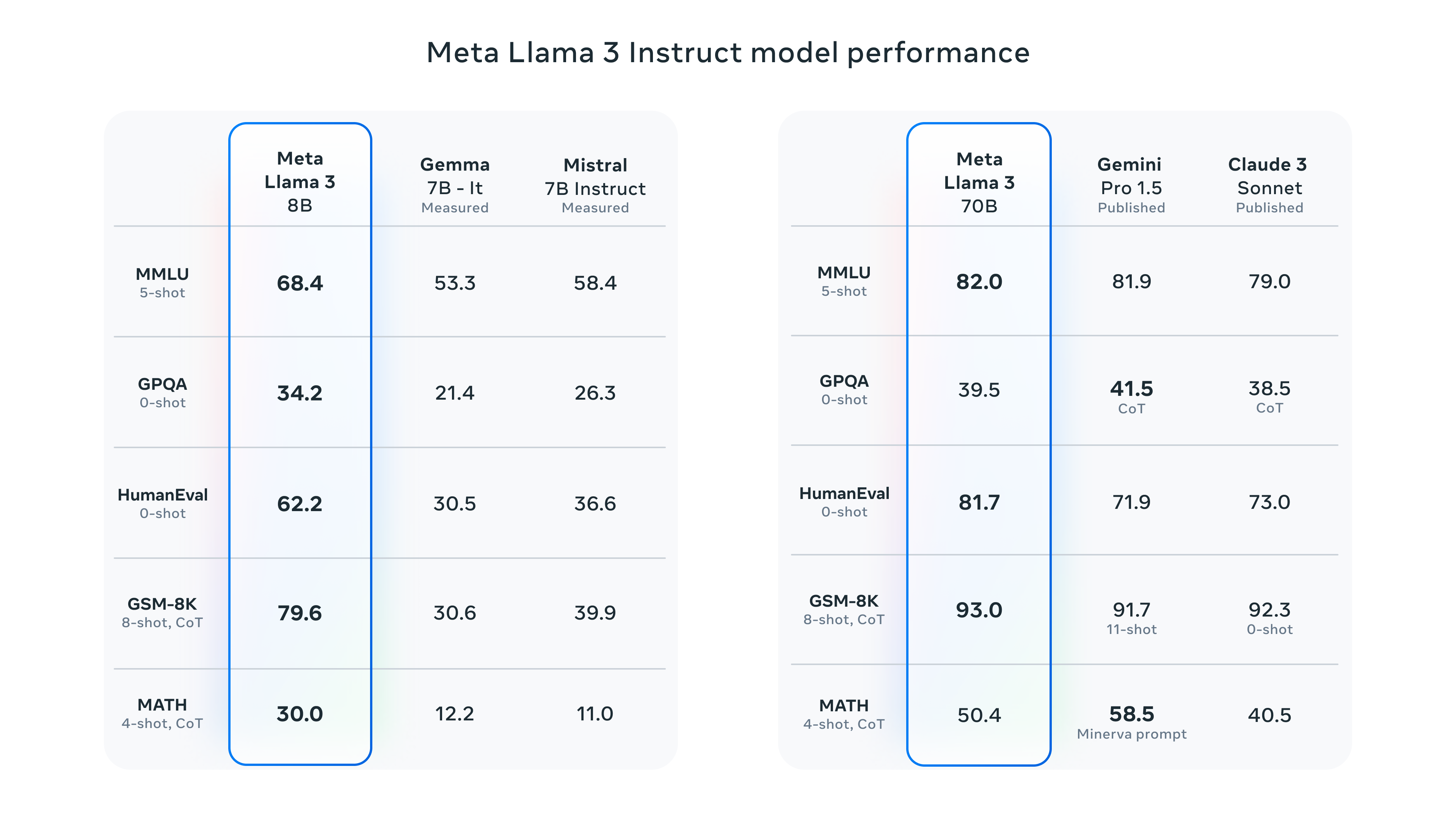
One thing that stood out to me is that both the 8B and 70B sizes match or exceed similar class models. The exciting difference, though, is that I can run the 70B parameter model locally on my laptop while this isn’t even an option for similar performing models like Google Gemini Pro 1.5, Claude 3 Sonnet, or OpenAI’s GPT-4. Meta also is actively training a larger 400B parameter model which will likely outperform these two releases. Very exciting time to be alive!
🔥🔥🔥
Let’s take a crack at getting this thing running locally. To do this let’s use Ollama.
What is Ollama
Ollama is the easiest tooling I’ve discovered for getting LLMs up and running locally on any hardware. It can be installed on macOS, Windows, and Linux by following instructions on their GitHub repo which boasts an impressive 57k stars.
Pulling the Models
I’m currently working on a MacBook, and to download the 7B parameter Llama 3 model I run the following command:
ollama pull llama3
pulling manifest
pulling 00e1317cbf74... 100% ▕███████████████████████████████████████▏ 4.7 GB
pulling 4fa551d4f938... 100% ▕███████████████████████████████████████▏ 12 KB
pulling 8ab4849b038c... 100% ▕███████████████████████████████████████▏ 254 B
pulling c0aac7c7f00d... 100% ▕███████████████████████████████████████▏ 128 B
pulling db46ef36ef0b... 100% ▕███████████████████████████████████████▏ 483 B
verifying sha256 digest
writing manifest
removing any unused layers
success
Just like that we downloaded the model weights.
Downloading the 70B parameter model takes a little longer since it’s 40GB, a little larger than the ~5GB 7B model. The 70B model can be pulled with ollama pull llama3:70b.
Chatting with the Model
Now that we have the model weights installed locally, let’s chat with it. To run a chat session from the terminal we run ollama run {model}. Let’s chat with the 70B parameter model!
ollama run llama3:70b
>>> Sally (a girl) has 3 brothers. Each brother has 2 sisters. How many sisters does Sally have?
A classic lateral thinking puzzle!
At first glance, it seems like a straightforward question: "How many sisters does Sally have?"
But wait... If each of Sally's 3 brothers has 2 sisters, that means each brother has Sally and one other sister.
So, in total, there is only 1 other sister besides Sally. Therefore, Sally has exactly 1 sister.
>>> Send a message (/? for help)
Not bad! Note that when asking this same question to Mistral 7B the model incorrectly answers 5.
ollama run mistral
>>> Sally (a girl) has 3 brothers. Each brother has 2 sisters. How many sisters does Sally have?
Let's break this down:
1. We know that Sally is a girl, and she has 3 brothers.
2. Each of her brothers has 2 sisters. So each brother is sharing those 2 sisters with Sally and the other brothers.
3. Since there are three brothers, and each brother has 2 sisters, then in total, they have 2 * 3 = 6 sisters. However, since we already know that Sally is one of them, we need to subtract her from the
count as she was not included in the "brothers" count.
4. So, Sally has 6 - 1 = 5 sisters.
>>> Send a message (/? for help)
I don’t know about you, but I’m looking forward to see how applications incorporate these powerful and accessible open source models into their business model. Ollama already boasts an impressive list of integrations that all have access to run these Meta Llama 3 models. What will you build with Meta Llama 3? 🤔💡