I was in the process of cloning the code for this website from github on a new laptop when I noticed something.
git clone git@github.com:NickHerrig/nickherrig.com.git
The repo was taking a noticable amount of time to clone. I timed how long it took and found that it was about 8.5 seconds!
Cloning into 'nickherrig.com'...
remote: Enumerating objects: 583, done.
remote: Counting objects: 100% (76/76), done.
remote: Compressing objects: 100% (50/50), done.
remote: Total 583 (delta 23), reused 72 (delta 22), pack-reused 507
Receiving objects: 100% (583/583), 78.74 MiB | 11.49 MiB/s, done.
Resolving deltas: 100% (226/226), done.
git clone git@github.com:NickHerrig/nickherrig.com.git 1.08s user 1.94s system 35% cpu 8.524 total
I had a gut feel it was related to the images that I’m storing in the repo, but I wanted to make sure.
To find out I ran a du -sh * to try and find the largest directory.
du -sh *
4.0K README.md
4.0K archetypes
88K content
4.0K hugo.yaml
74M static
0B themes
From here I noticed that my static directory was 74M. Gut feel confirmed. This is where I store all my blog images. A little more digging showed that I was storing 26M of images from my most recent blog post Kauai Hawaii - Part One: Adventures. As I look forward to writing more blog posts with image content, I realized this doesn’t really scale well with the usability of my git repo. I started doing a little research and decided to tackle this problem in two ways.
Image Resizing and Formating
When I realized my images were pretty large, I wanted to confirm this with another form of analysis. I reached for a popular tool called PageSpeed Insights. You can use this tool to run an analysis on specific pages of a website to get a report on performance issues.
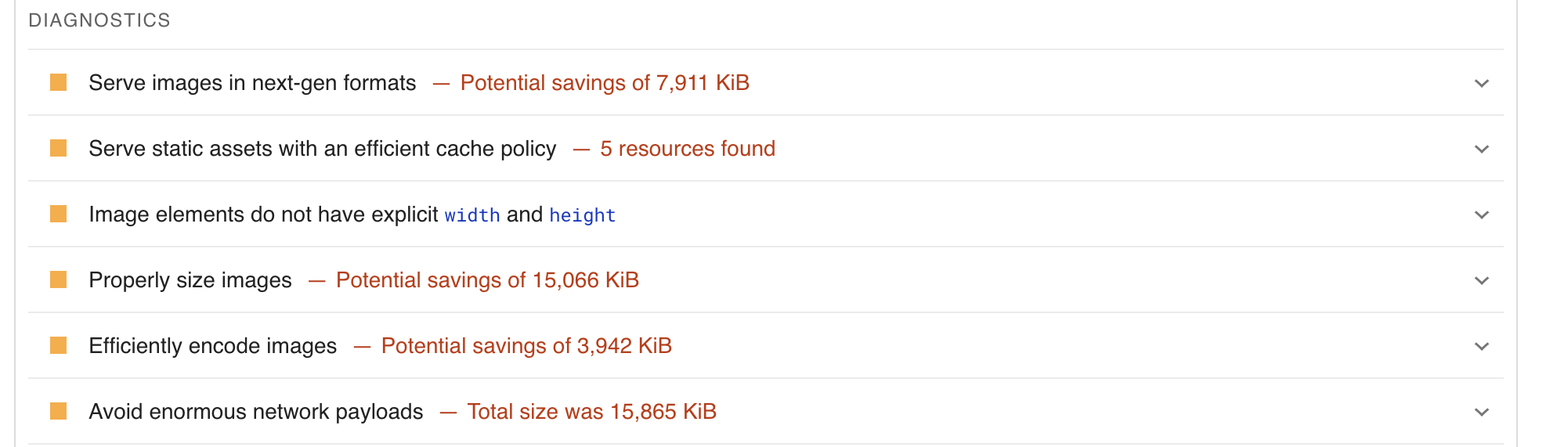
One call out was to utilize next-gen formats like webp. Another call out was to properly size the images. I decided to write a quick shell script to change the form of my images fro jpg to webp and reduce the quality.
for img in *.jpg; do
magick convert "$img" -quality 80 "${img%.jpg}.webp"
done
With that, we’re down to 11M from 26M! Not bad! Next, I wanted to resize the images. In order to do this, I needed to first identify the current size of the images, then figure out what the computed values were on the website. To run this example, let’s look at the caves image.
identify -format "%wx%h\n" caves.webp
4032x3024
When looking at the deployed production site, the same image height was 540px and width was 720px. This means we can resize to the computed value, and maybe even get away with bumping the quality to 100%. Let’s try it out.
du -sh caves.webp
1.8M caves.webp
magick caves.webp -resize 720x540 -quality 100 _caves.webp
du -sh caves.webp _caves.webp
1.8M caves.webp
496K _caves.webp
And just lke that we’ve saved a ton of space, and my human eyes cannot tell the difference! I’ll spare you the repetitveness of doing this to every image in my repo for the purpose of this blog.
The Numbers
Now when I take a peak at my static directory here’s what I see.
du -sh *
4.0K README.md
4.0K archetypes
84K content
4.0K hugo.yaml
4.1M static # Used to be 74M
792K themes
Going from 74M to 4.1M with literally zero implication to noticable image quality is pretty great!
Let’s take a look now at how long it takes to do a git pull.
Cloning into 'nickherrig.com'...
remote: Enumerating objects: 720, done.
remote: Counting objects: 100% (213/213), done.
remote: Compressing objects: 100% (145/145), done.
remote: Total 720 (delta 60), reused 202 (delta 54), pack-reused 507
Receiving objects: 100% (720/720), 97.09 MiB | 9.78 MiB/s, done.
Resolving deltas: 100% (263/263), done.
git clone git@github.com:NickHerrig/nickherrig.com.git 1.29s user 2.23s system 29% cpu 11.739 total
Shit, it appears we went backwards here from 8.5 seconds to 11.8 seconds. I’m assuming this is because git stores a history of changes to the repo, so all we really did here was add a bunch of smaller images to the repository. Enter git LFS.
Git LFS
Git Large File Storage (LFS) is a tool that helps keep your repository light by storing large files separately from your main git repo. Here is a direct quote from the documentation on how it works.
Git LFS handles large files by storing references to the file in the repository, but not the actual file itself. To work around Git’s architecture, Git LFS creates a pointer file which acts as a reference to the actual file (which is stored somewhere else). GitHub manages this pointer file in your repository. When you clone the repository down, GitHub uses the pointer file as a map to go and find the large file for you.
In order to get this working for my GitHub Pages hosting, it appears that with this GitHub Discussion all you need to do is add a little configuration to your github actions.
- name: Checkout
uses: actions/checkout@v4
with:
lfs: true
At this point, I made sure to initialize git LFS and track specific file types.
git lfs install
git lfs track "*.jpg"
git lfs track "*.jpeg"
git lfs track "*.png"
git lfs track "*.webp"
git lfs track "*.mp4"
git lfs track "*.mp3"
Since git lfs only starts tracking newly added files, we’ll want to migrate our existing files. We can do this by running.
git lfs migrate import --include="*.jpg,*.jpeg,*.png,*.webp,*.mp4,*.mp3" --everything
git push --force
And just like that, we’ve improved the speed of our repo clones from 11.8 seconds to 4 seconds.
Cloning into 'nickherrig.com'...
remote: Enumerating objects: 867, done.
remote: Counting objects: 100% (397/397), done.
remote: Compressing objects: 100% (237/237), done.
remote: Total 867 (delta 129), reused 393 (delta 127), pack-reused 470
Receiving objects: 100% (867/867), 10.11 MiB | 10.48 MiB/s, done.
Resolving deltas: 100% (316/316), done.
Filtering content: 100% (36/36), 3.08 MiB | 1.85 MiB/s, done.
git clone git@github.com:NickHerrig/nickherrig.com.git 0.34s user 0.50s system 20% cpu 4.076 total
Cheers to Saturday optimizations! 🍺